2022 ICME小样本商标检测挑战赛
赛题分析
任务:
利用少量有标注的训练样本,检测出商标的位置和类别。
数据简介:
训练集合:共3500张训练图片,100类商品品牌logo,7千多个实例。初赛50类,每类50张训练图片;复赛50类,每类20张训练图片。
评价指标:
$mAP(Iou=.50:.05:95)$
预训练模型:
ImageNet 1K
难点
- 小目标
解决方案:- 高分辨率
- Global Context
- 类间差异大
解决方案:- 数据增强
- 大模型
方案介绍
框架

数据端:Copy-Paste & Mixup
Copy-Paste:
如果一张图像内的 bbox 数量少于 6,则随机复制粘贴部分 bbox
Mixup:
以 0.5 的透明度混合两张图
数据端:Multi-Scale
1 | dict( |
1 | test_pipelin = [ |
数据端:初赛数据
- 预训练 100 epoch + 12 epoch
- 将初赛训练集中与复赛数据中相同的三类图像加入训练
1
2
3
4
5cat_id_map = {
33 Diadora/迪亚多纳 : 33 Diadora/迪亚多纳 ,
26 BOY LONDON : 31 BOY LONDON,
23 JORDAN : 14 Nike/耐克
}
模型端:
Backbone & Neck: ConvNeXt & RFP
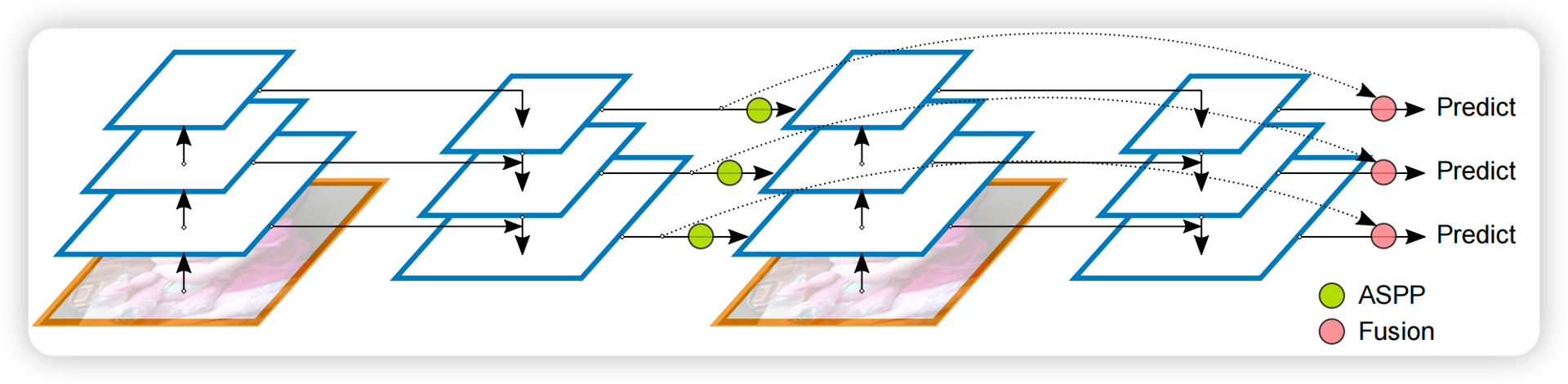
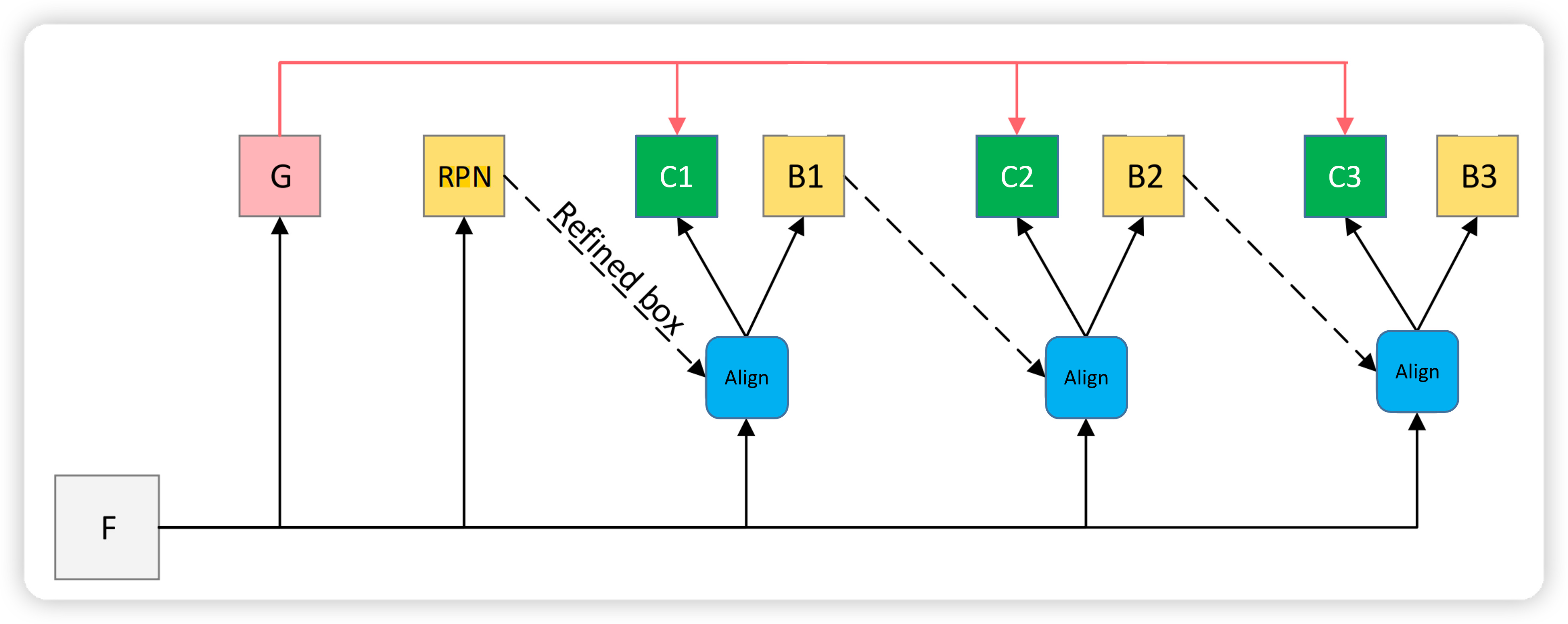
RPN Head

Roi Head: Double Head Cascade Roi Head
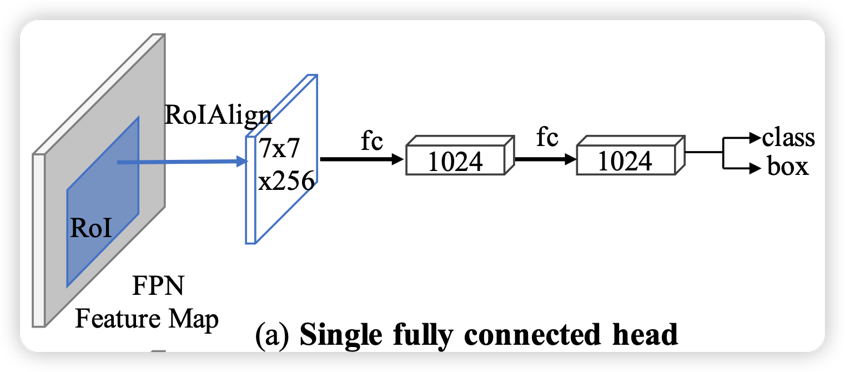
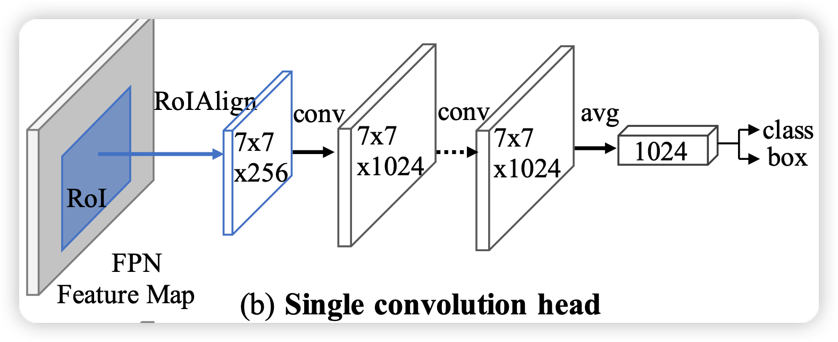
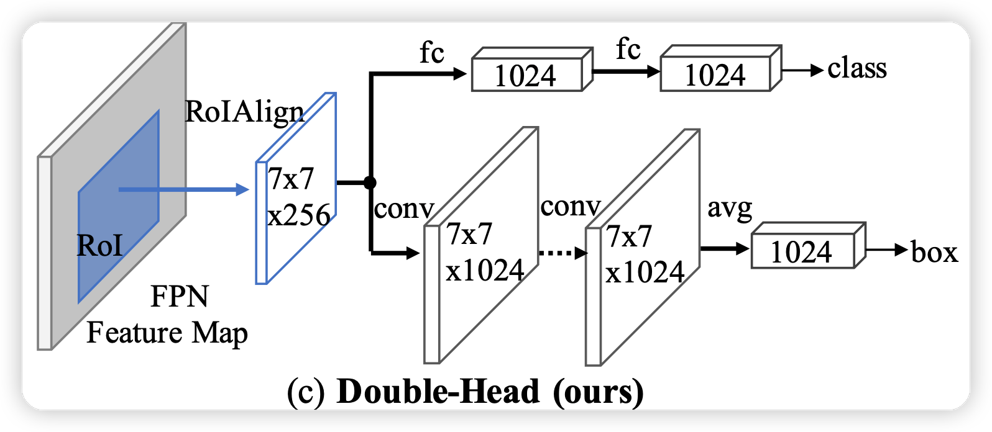
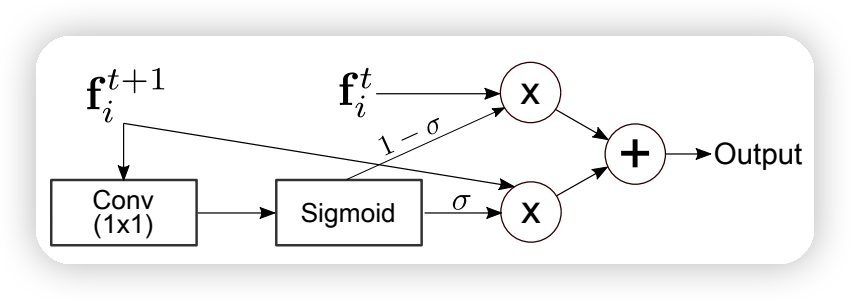
Roi Head: + Global Context
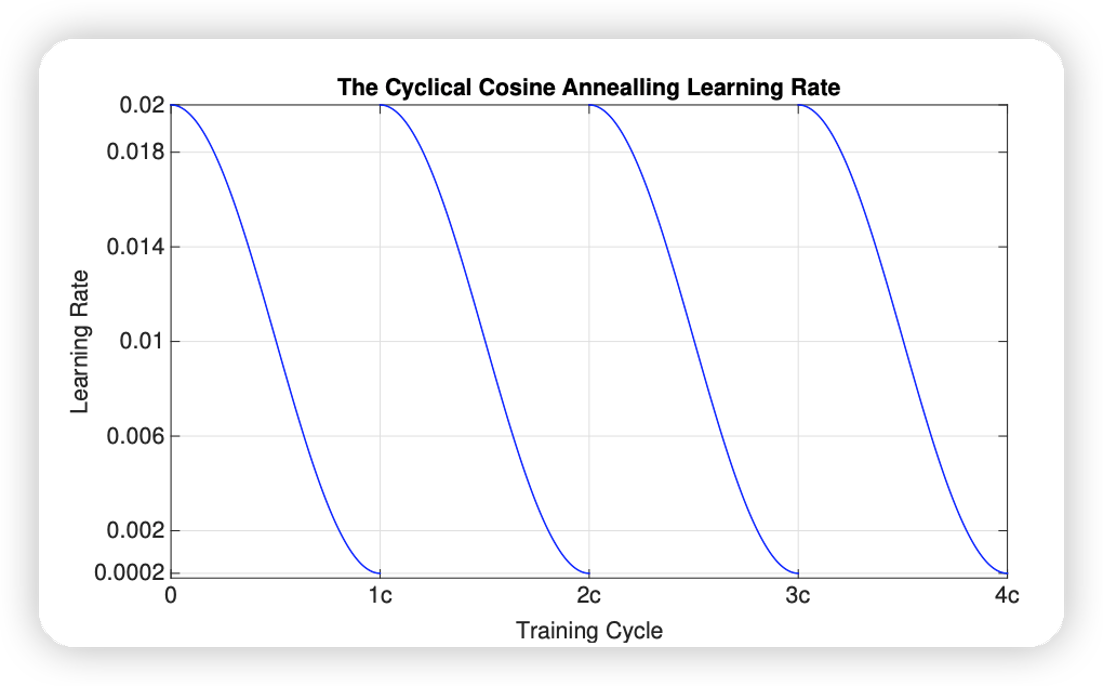
SWA
后处理: 将 score 最高的类别认为是该图的类别,将不同类别的 score * 0.001

比赛总结
- 针对小目标:
随机裁剪 + 多尺度训练,Global Context - 针对小样本和类间差异大:
大量数据增强 + 大模型- Copy-Paste, Mixup, AutoAugment V2
- ConvNeXt-Base + RFP
- 泛化能力:
SWA - 数据先验:
后处理





